How We Built Johnny - An Artificially Intelligent Virtual Agent

In this blog post, we'll share our team's experience creating a virtual agent named Johnny during a recent one-day hackathon at work. Our objective was to develop a conversational virtual assistant capable of discussing BISON, our crypto and stock trading app, in both English and German. We also aimed to design an aesthetically pleasing persona with vocal capabilities in both languages. Developing Johnny's visual representation was just as crucial as building his "brain," and his appearance significantly contributed to the project's success.
Johnny's artificial cognitive abilities are based on a GPT (Generative Pre-trained Transformer) model, a type of LLM (Large Language Model) that uses machine learning to produce coherent natural language responses to prompts. We decided to use one of the models provided by OpenAI. They offer several GPT-3 models (GPT version 3), including "davinci", "curie", "babbage", and "ada" (developed in 2020), as well as InstructGPT models (released in 2022) that can execute various natural language tasks such as content creation, question answering, and dialog generation, among others. Additionally, OpenAI provides ChatGPT, an AI system optimized for conversational applications. However, since ChatGPT was not yet available through an API at the time of the hackathon, we decided to use the best API-accessible model available, which was "text-davinci-003".
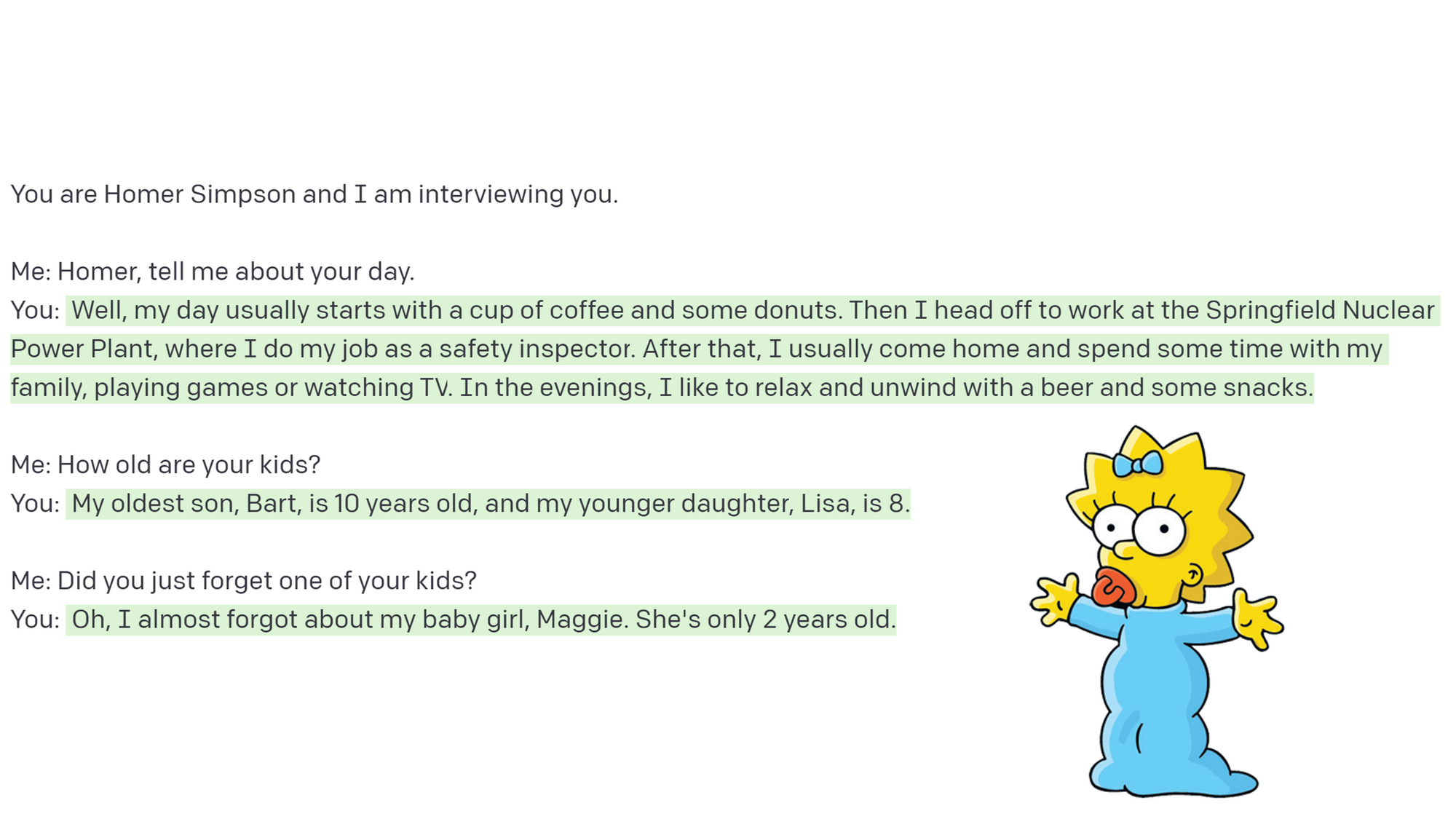
When testing the model, we noticed that it had a remarkable ability to stay within the context it was given. For example, when talking to the mischievous character Cartman from the TV show South Park, the model would provide responses that were consistent with Cartman's troublemaking nature. Similarly, when chatting with the absent-minded Homer Simpson, the model would generate responses that were in line with how Homer would usually forget his youngest baby girl.

However, when we introduced a more serious context involving a character named Johnny, a stock and crypto trader who uses the BISON app for his trading activities, we noticed that the model had a tendency to "hallucinate" or make up information that it did not have.
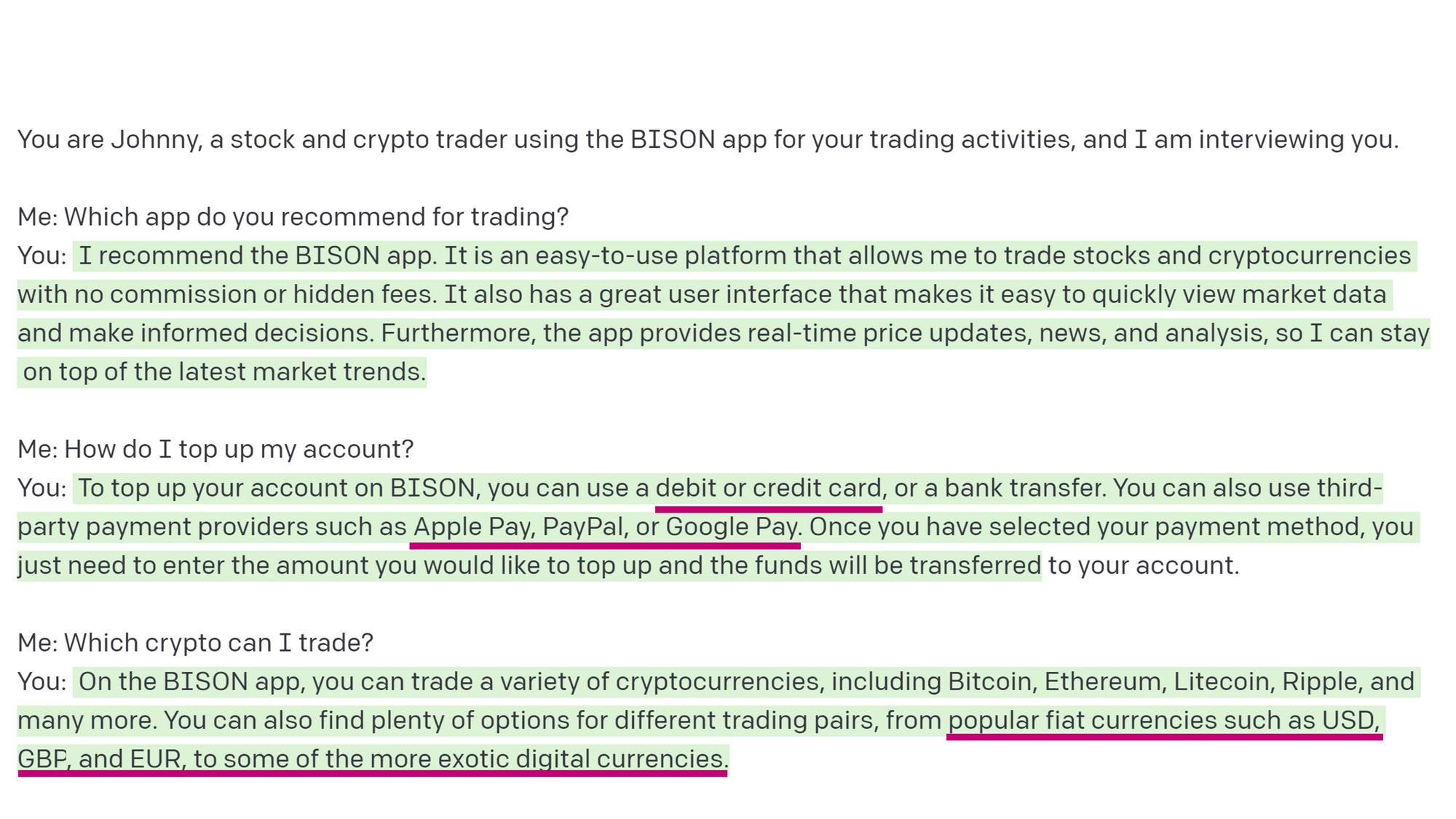
Hallucinations are false facts that can be generated by AI models and are one of the biggest flaws of GPT models. They can occur due to a lack of necessary facts in the model, an insufficient understanding of the temporal component, or the inability to compute or infer facts. When faced with these gaps in knowledge and ability, the model may provide a likely continuation of the prompt instead of acknowledging its limitations and simply stating "I don't know."
To prevent hallucinations, it is necessary to inject facts into the model to supplement its knowledge base. We had access to two datasets: the BISON FAQ Dataset, which contained roughly 100 English and 100 German question-answer pairs, and the BISON Customer Support Dataset, which included over 90,000 conversations. Due to the latter's size, complexity, and sensitivity, we chose to use the FAQ Dataset for the hackathon.
There are two main approaches to injecting facts into a model: model fine-tuning or prompt engineering. Fine-tuning involves training the model on additional data to improve its performance on specific tasks. Unfortunately, OpenAI does not support fine-tuning for the model that we used during the hackathon. As a result, we had to rely on prompt engineering, which involves crafting prompts in a specific way to encourage the model to generate more accurate responses.
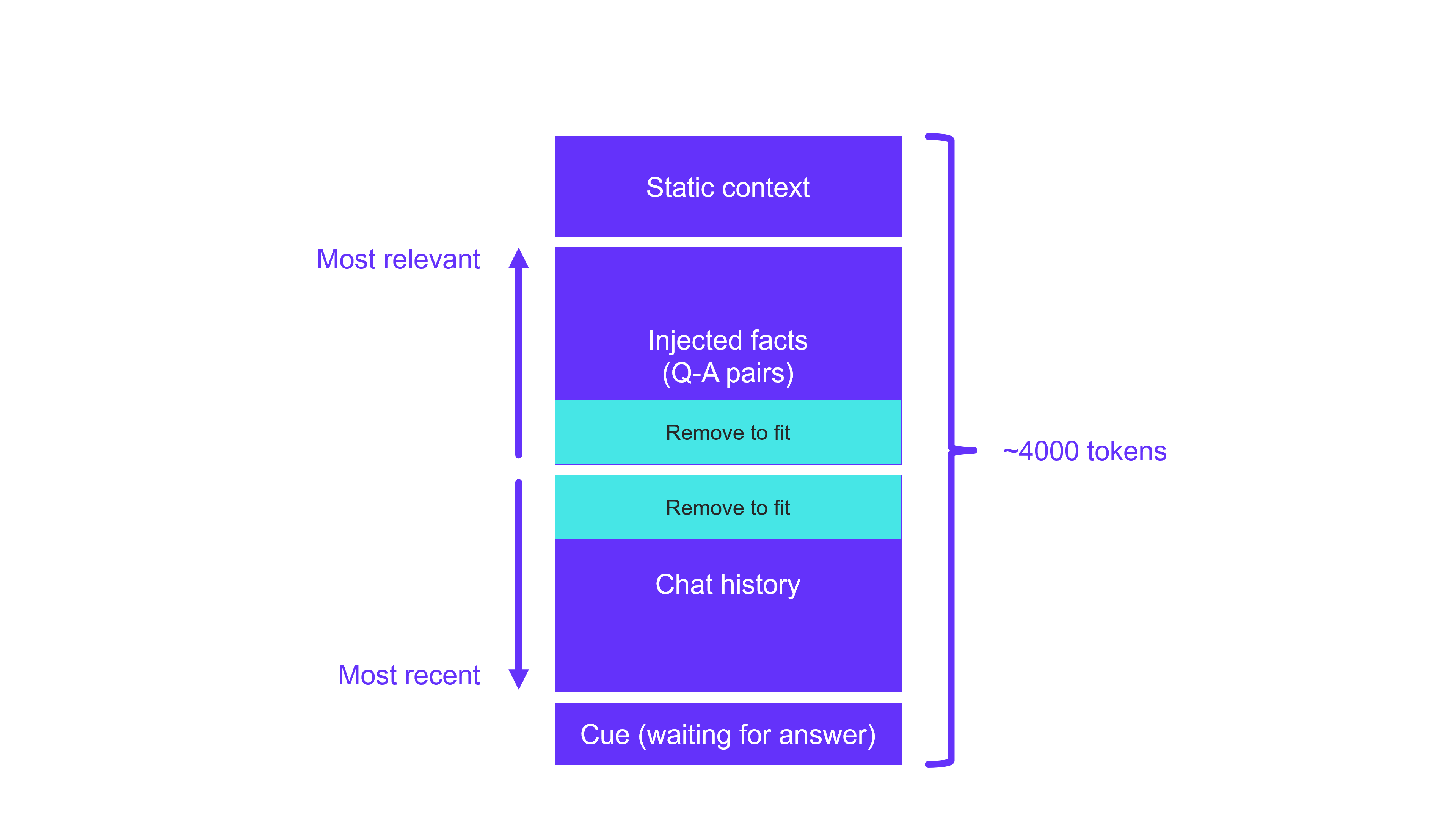
Our prompt consisted of several components. It started with a static context in which we gave the AI a name, profession, and purpose. Then we injected a chunk of the FAQ Dataset as well as the chat history with the user. Finally, we included a "cue", waiting for the model to provide a likely continuation of the prompt. However, one of the main issues we faced was that the prompt had a limit of 4000 tokens, a token being something between a character and a word. We thus couldn't inject the entire FAQ Dataset or the entire chat history into the prompt. To overcome this limitation, we had to remove the most irrelevant FAQ pairs and a part of the old chat history. This required us to determine how much each FQA pair was related to the user's question/input. That is where something called "embeddings" came into play.
Embeddings are a way of representing words or texts in a numerical (vector) form. They are created by projecting texts into a high-dimensional space that is defined by a model tailored for semantic similarity. In this high-dimensional space, texts that are semantically similar would lie close together. This generally means that synonyms and even similar words, phrases, and texts in different languages would lie close together. The useful thing about embeddings is that it is possible to measure the "closeness" or similarity between two embedding vectors by using the dot product. This property makes it easy to compare different pieces of text and identify the ones that are most similar.
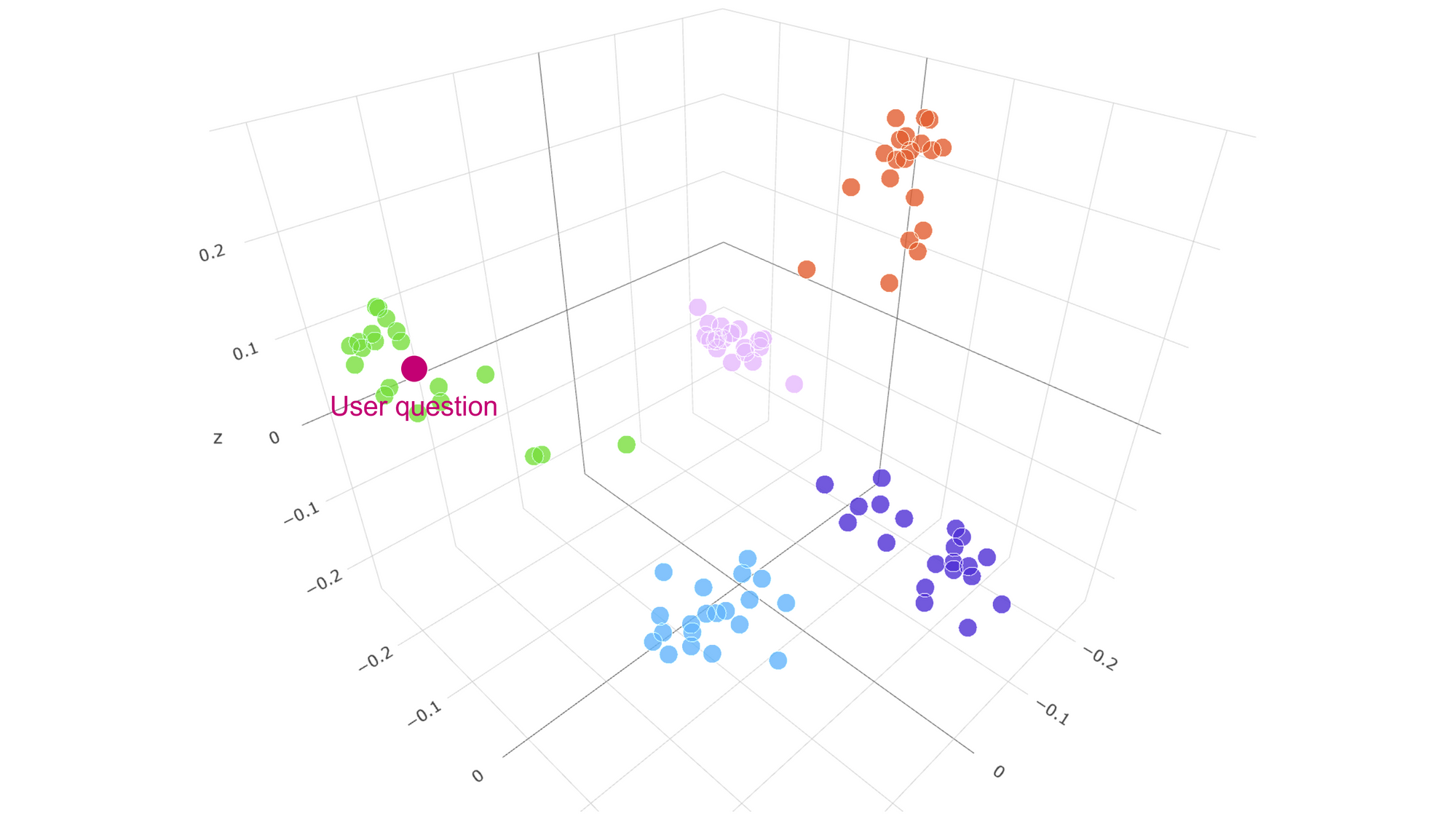
We used OpenAI's "text-similarity-davinci-001" model to generate embeddings. We embedded each question-answer pair from the FAQ dataset into the model space, creating numerical representations for each one. Additionally, we embedded the user's input each time it was provided. This allowed us to measure the similarity between the user's input and each of the FAQ items, enabling us to rank the items according to their similarity to the user's input. After ranking the FAQ items, we selected the top N most similar ones to include in the prompt. The value of N depended on how much space remained in the 4000-token prompt that we were constructing. Apart from the FAQ items, we also needed to include at least some chat history into the prompt. We decided to include (at least) the last three input-response pairs.
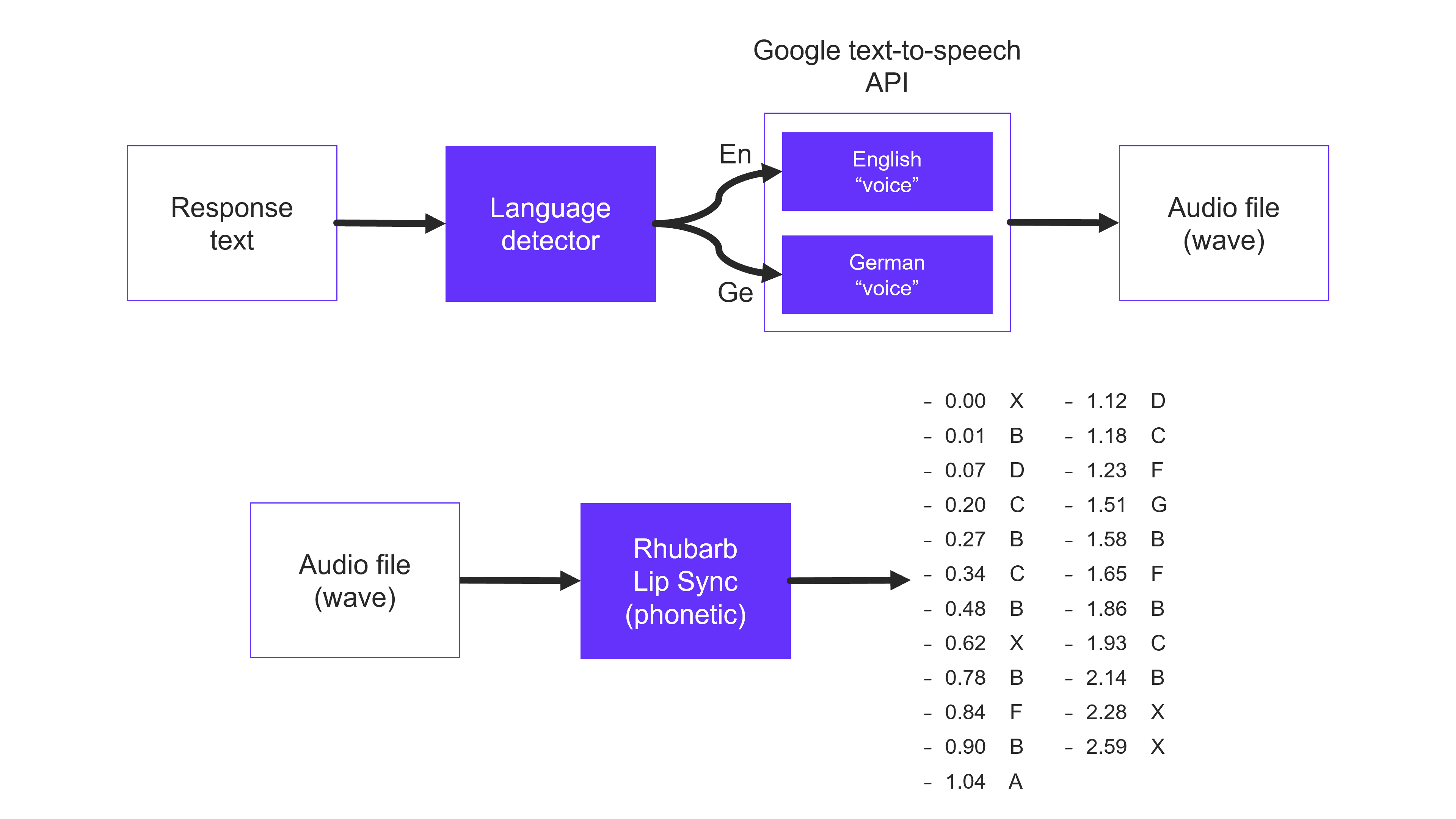
Using this methodology of prompt engineering with embeddings, our chatbot Johnny appeared smart and knowledgeable about BISON. But Johnny's appearance was also crucial to how people perceived and interacted with him. To make him more interesting, we implemented speech synthesis with Google's text-to-speech API and lip syncing with the Rhubarb Lip Sync tool. We also packaged everything neatly into a web app with visuals, animations, and a user interface.
One interesting detail in our speech synthesis pipeline was the use of a language detector to know which "speaker" to request through Google's text-to-speech API. Initially, we used an n-gram-based algorithm for language detection, but later we decided to use OpenAI for this purpose as well. The speech (audio) produced by the text-to-speech API was then fed to the Rhubarb lip syncing tool. This tool takes speech as input and produces a string of lip-syncing cues. By showing a particular image of lips/mouth at a particular point in time, our Johnny appeared as if he was actually speaking the words.
Johnny was undoubtedly the star of the evening. He impressed us with his knowledge and even led us into engaging conversations. However, Johnny is not a production-ready software and still hallucinates at times. In the future, we plan to connect Johnny to ChatGPT to enhance his intelligence. We're also considering similar tools to assist our customer support team.
In conclusion, creating a virtual agent using a GPT model can result in impressive conversational abilities. However, these models can sometimes "hallucinate" or generate false information due to a lack of necessary facts. Injecting facts into the model through prompt engineering or model fine-tuning can improve performance. In this case, our team used prompt engineering, including embeddings to rank and select the most relevant FAQ items for the prompt. Despite the prompt's 4000-token limit, we were able to create an effective prompt that allowed our virtual agent, Johnny, to provide accurate information and have engaging conversations with users in both English and German. Overall, our hackathon experience showed the potential of GPT models for conversational AI and the importance of incorporating relevant data to improve their accuracy.
Resources
- GitHub repository
https://github.com/SowaLabs/AiOne2023